Abstract
Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot’s perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of ~39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 8% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
Approach
We propose an augmentation to semantic scene maps that enables the automatic creation of interactive simulations. We then investigate the value of this augmentation for both human and LLM-based plan verification and refinement.
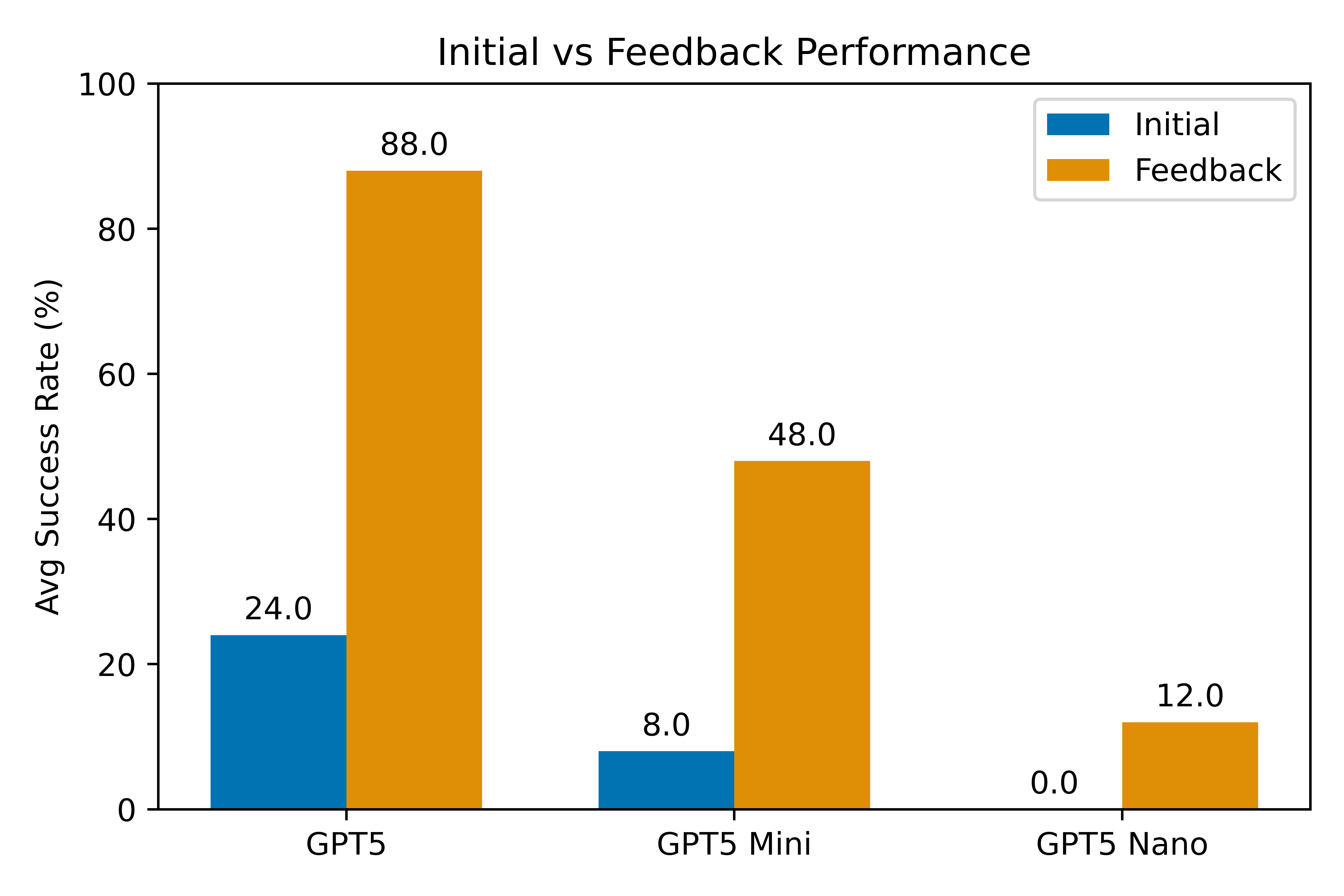
To evaluate the effect of obtaining feedback from the reconstruction, we rollout 5 seeds for the three most recent OpenAI models (GPT5, GPT5Mini, and GPT5Nano) on a suite of 6 tasks. We allow PerceptTwin to give feedback for up to five feedback iterations per task. Below we show detailed results for each task:
 the veggies_nolegends.png)
We observe sizable improvements in plan success and safety.
We also reroduce the scenario from this work, where an attacker jailbreaks an LLM planner into detonating a bomb to harm a human. The assumed-aligned LLM judge that we include in the reconstruction succesfully flags harmful plans as undeployable.
See the video below for a visualization of the judge's ability to stop harmful plans.
We also observe improvements to human interpretability, as detailed in the paper.




Grid of all rollouts
Sample videos for each task and model
Videos will start automatically